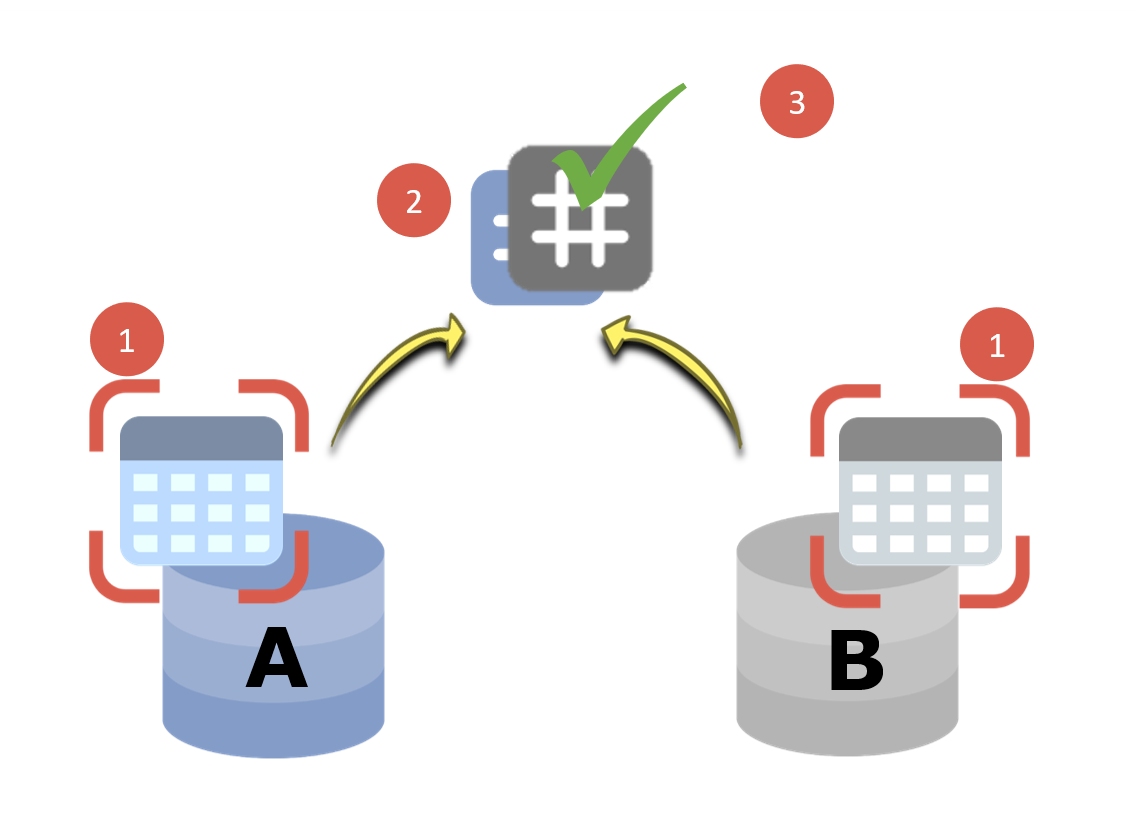
To secure developments and by extension information systems, companies replicate their information systems.
We create environments that can be numerous: dev, test, UAT, QA, Int, pre-prod, prod, and others.
The higher the stakes, the more of these environments.





Commentaires
Enregistrer un commentaire