Remove regressions: identify unnecessary tables and views!
 Remove regressions between IT environmentsDelete unnecessary tables and views!
Remove regressions between IT environmentsDelete unnecessary tables and views! The profusion of tables and viewsMany companies dream of being “data driven”. And rightly so.More and more data is collected by more and more means by taking advantage of Cloud architectures, which are infinitely scalable.This data is largely exploited by data scientists who must build new "business insights", and who legitimately ask IT to make more and more data available.Often, the data is replicated, by retouching at the margin and this phenomenon is accentuated during the implementation of “data mesh” architectures in the Cloud.On the IT side, data engineers do not always resume the work of their predecessors, often starting developments "from scratch". And the imperatives of speed increase this drift.The impact on deployments
The profusion of tables and viewsMany companies dream of being “data driven”. And rightly so.More and more data is collected by more and more means by taking advantage of Cloud architectures, which are infinitely scalable.This data is largely exploited by data scientists who must build new "business insights", and who legitimately ask IT to make more and more data available.Often, the data is replicated, by retouching at the margin and this phenomenon is accentuated during the implementation of “data mesh” architectures in the Cloud.On the IT side, data engineers do not always resume the work of their predecessors, often starting developments "from scratch". And the imperatives of speed increase this drift.The impact on deployments Forester indicates in a 2022 survey that between 60% and 73% of all data in a company is not useful for analytics!When it comes to organizing deployments, IT teams will find themselves moving “dead matter” unnecessarily from one environment to another. Shame.Our technical approach
Forester indicates in a 2022 survey that between 60% and 73% of all data in a company is not useful for analytics!When it comes to organizing deployments, IT teams will find themselves moving “dead matter” unnecessarily from one environment to another. Shame.Our technical approach
"Le data lineage"&
"Uses of information",To identifyunnecessary tables and views!{openAudit} specializes in dynamic reverse engineering of data processing technologies and log analysis.1 - Analysis of logs to identify tables that have a use:{openAudit} will detect through the logs all tables and viewsthat actually feed dataviz solutions. The scan of dataviz solutions makes it possible to know which "physical" data are in source (i.e. a table/field of a DB, an Excel doc, a webservice etc...) of the dashboards, which are queried via ad hoc queries.2 - The data lineage to identify all the sources of the tables that have a use:- {openAudit} analyzes views; views of views, etc.,
- {openAudit} manages dynamic procedures by processing the dynamically constructed SQL based on the logs of the DB, or the tool that generates these queries,
- {openAudit} fix other break generators in the lineage: FTP transfers, cursors, subqueries, etc., by various internal mechanisms,
- {openAudit} processes SQL wrapped in ELT/ETL jobs which creates a lot of opacity,
Even when processing technologies are intertwined (ELT/ETL, object/procedural languages, Cloud/on prem'), {openAudit} makes it possible to recreate overall consistency. Some tools (ETL/ELT) offer data lineage on their perimeter, but are unable to connect other data lineage tools to it, or even to associate analyzes between projects.Thus through this data lineage, coupled with the analysis of the logs, all the tables | useful views vs those that are "informational dead ends" are identified (up to 50%!), ...... And can be decommissioned!... for ever easier changes of environmentWe saw that it was possible to generate a unique hash per table | view including the order of the fields, the types of fields, the normalization of the script of the views to control the changes of environmentThis precise control, associated with the detection and mass eviction of tables & views that have no use, will significantly simplify these environment switches.Film : erase IT debt - 1'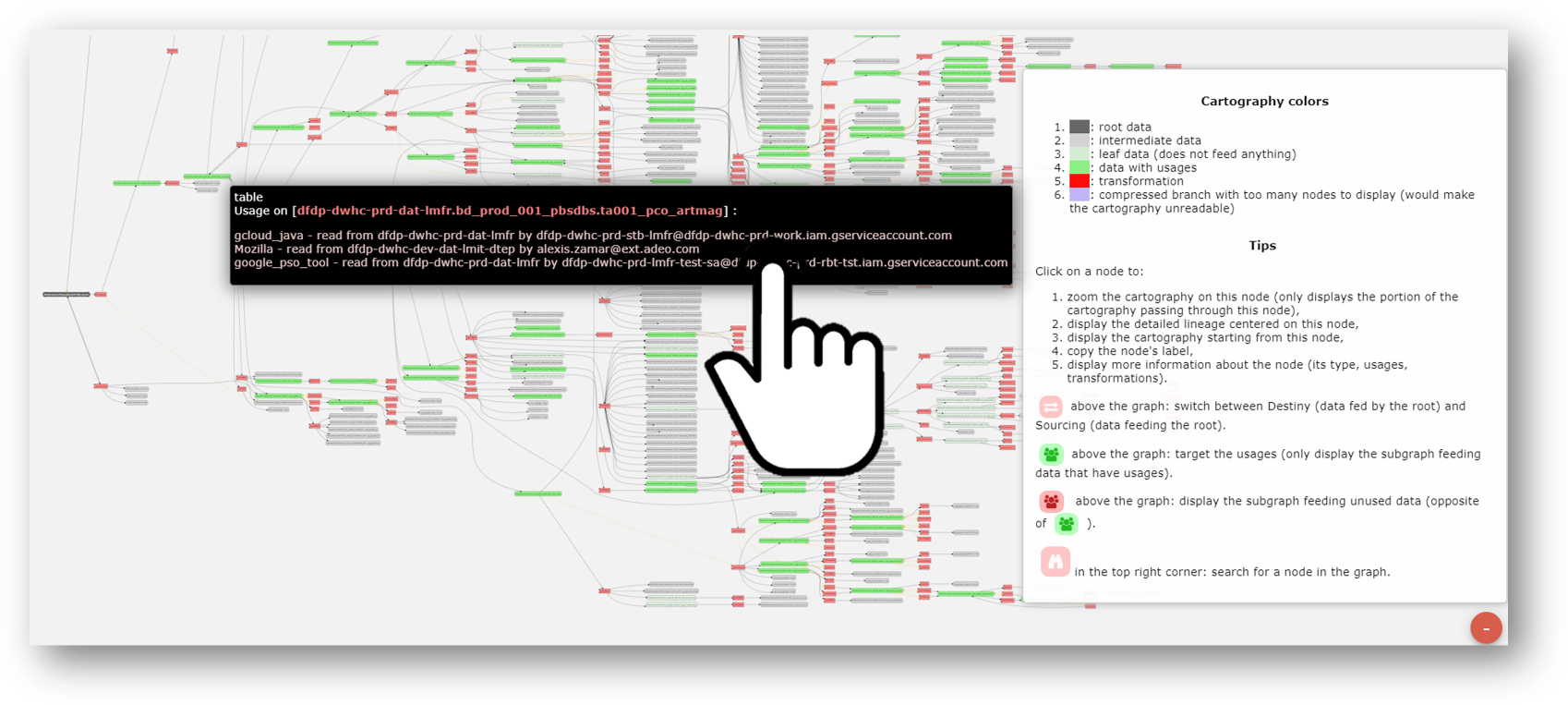



Commentaires
Enregistrer un commentaire