Migrate a legacy to the Cloud, then keep control!
 Migrate a legacy to the Cloud, then keep control!
Migrate a legacy to the Cloud, then keep control!
- Migrating a legacy - a technical challenge!
- Many companies have migrated to the Cloud, massively choosing hyperscalers. For others, it's still a project, with big pitfalls that slow down or largely cause projects to fail.The technical difficulties of such a project are numerous:
- How to define in continuous time the existing one with all its dependencies;
- How to know what has been migrated, what remains to be migrated, how to compare responses;
- How not to create "load breaks";
- How to enable teams of data engineers to collectively control the migration process;
....  Stage #1 :
Stage #1 :
Truly mastering your legacy- {openAudit} will analyze the source platform daily.
- By relying on parsers and probes that work continuously, {openAudit} allows ultra-granular daily analysis of the legacy, as well as all the data visualization solutions connected to it.
- In detail, {openAudit} will highlight:
- Internal processes via physical data lineage, at a field level, in the source language (Cobol, Bteq, PL/SQL, others), but also the jobs of the ETL/ELT used, Views, Macros, other associated scripts flows;
- The uses of the information, via an analysis of the logs of the audit databases;
- Task scheduling;
- The impacts in the data visualization tools that are associated with the Legacy System, to glimpse the related complexity (calculation rules), and to be able to do data lineage from operational sources to the dashboard cell.
- Stage #2 :
Control the deployment in the target platform
- {openAudit} will also continuously analyze the target platform in the Cloud.
- Like the source platform, {openAudit} will operate different actions on the target platform to measure its evolution during the migration, and beyond:
- Dynamic parsing (= scanning) of BigQuery, Redshift, Azure SQL, others*, scheduled queries, view scripts, and Json, CSV, etc. type load files, to build streams with precision.
- Analysis of logs in Google Cloud's Operations (Stackdriver), in CloudWatch for AWS, in Monitor for Azure, others*, to immediately know the uses of the information.
- Introspection of certain "target" data visualization technologies* which are based on the Cloud platform (typically Looker, Data Studio for GCP, or PowerBI for Azure, etc.), in order to be able to reconstruct the "intelligence" therein by comparing the responses;
For an optimal understanding of changes in the information system, we provide a multi-platform map (source and target), which will present the flows and uses of information.* Some of our answers are under development. 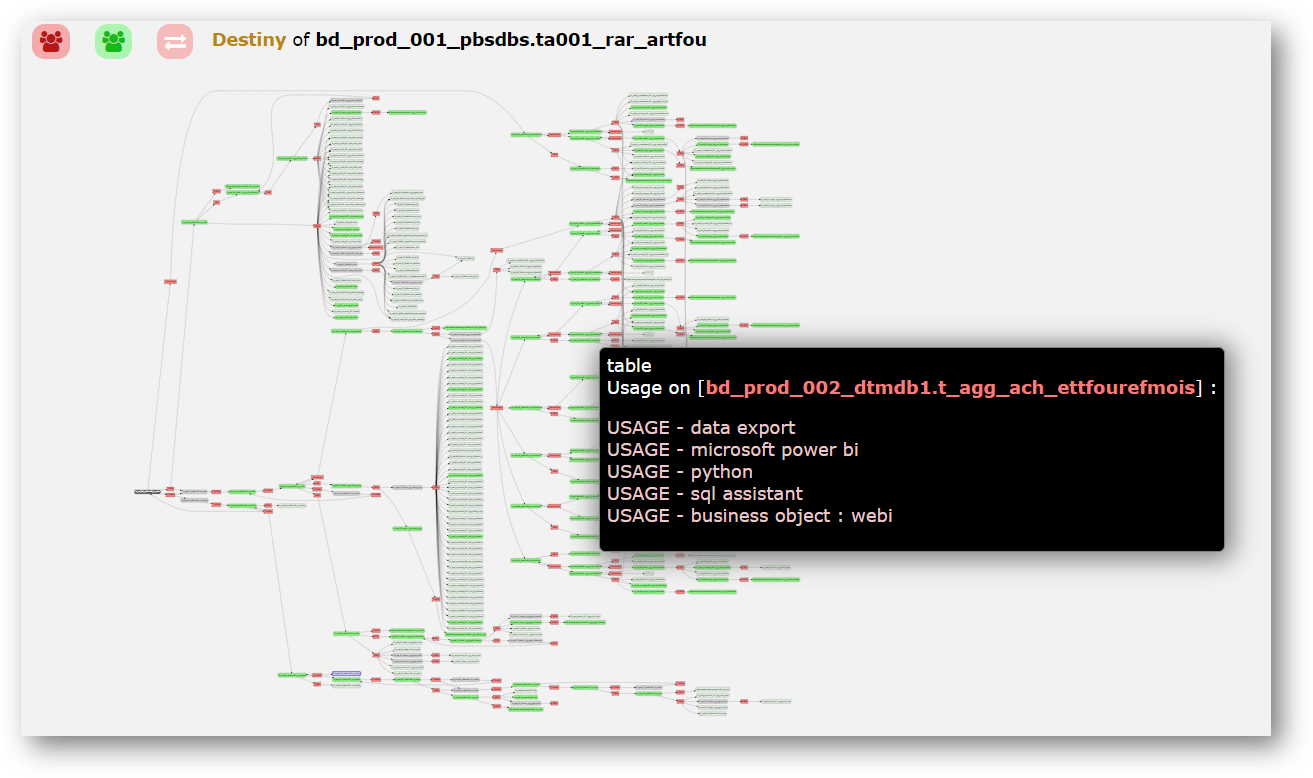
 Stage #3 :
Stage #3 :
"Translate" the source language to the target language- - {openAudit} will "parse" T-SQL, PL/SQL, Cobol, Perl, and any other procedural language, and break down all the complexity of the source code,
- -{openAudit} deduces the overall kinematics and intelligence,
- - On this basis, {openAudit} will produce "standard SQL",
- - Then the intelligence will be reconstructed at least in the specific SQL of the target database (which are SQL "dialects"!),
- - All complex processing that cannot be reproduced in simple SQL will be driven by a NodeJS executable.
- It is thus possible to massively accelerate the tempo of its migration!
- And once in the Cloud?The risk of informational inflation with "Data Mesh" type cloud architectures:The objective of the Data Mesh is to promote maximum flexibility, to create new "business insights", with ready-to-use data, validated by their functional owners. And it is effective! Some companies aspire to become "data driven", and the Data Mesh is a powerful catalyst for this strategy.However, the imperatives of mastering the processing of data in feed chains, which are in fact hyper intricate, can quickly become a "pain point" and make the strategy perilous!
- The experience of ADEO/Leroy MerlinTeradata > Google Cloud Platform

ellipsys@ellipsys-bi.com
www.ellipsys-bi.com



Commentaires
Enregistrer un commentaire