Migrer un legacy vers le Cloud, puis garder le contrôle !
 Migrer un legacy vers le Cloud, puis garder le contrôle !
Migrer un legacy vers le Cloud, puis garder le contrôle !
- Migrer un legacy - un défi technique !
- De nombreuses entreprises ont migré vers le Cloud, choisissant massivement les hyperscalers. Pour d'autres, c'est encore un projet, avec de gros écueils qui ralentissent ou qui font largement échouer les projets.
Les difficultés techniques d'un tel projet sont nombreuses :- Comment définir en temps continu l'existant avec toutes ses dépendances ;
- Comment savoir ce qui a été migré, ce qui reste à migrer, comment comparer les réponses ;
- Comment ne pas créer de "ruptures de charge" ;
- Comment permettre aux équipes de data engineers d’avoir collectivement la maîtrise du processus de migration ;
- ...
 Etape #1 :
Etape #1 :
Véritablement maîtriser son legacy- {openAudit} va analyser quotidiennement la plateforme source.
En s'appuyant sur des parsers et de sondes qui travaillent en continue, {openAudit} permet une analyse quotidienne ultra granulaire du legacy, ainsi que de toutes les solutions de data visualisation qui y sont raccordées.Dans le détail, {openAudit} va mettre en lumière :- Les processus internes via un data lineage physique, au champ, dans le langage source (Cobol, Bteq, PL/SQL, autres), mais aussi les jobs de l'ETL/ELT utilisé, les Vues, les Macros, les autres scripts associés aux flux ;
- Les usages de l'information, via une analyse des logs des bases d'audit ;
- L'ordonnancement des tâches ;
- Les impacts dans les outils de data visualisation qui sont associés au Système legacy, pour entrevoir la complexité afférente (règles de calcul), et pour pouvoir faire du data lineage des sources opérationnelles jusqu'à la cellule du dashboard.
- Etape #2 :
Maîtriser le déploiement dans la plateforme cible.
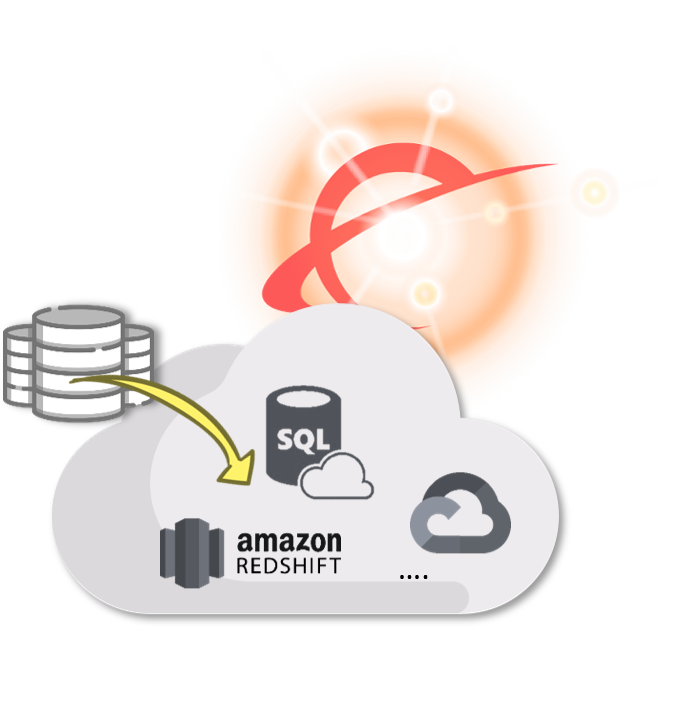
- {openAudit} va parallèlement analyser en continu la plateforme cible dans le Cloud.Au même titre que la plateforme source, {openAudit} va opérer différentes actions sur la plateforme cible pour en mesurer l'évolution au cours de la migration, et au-delà :
- Parsing (= scan) dynamique de BigQuery, Redshift, Azure SQL, autres*, des requêtes schedulées, des scripts des vues, et des fichiers de chargement type Json, CSV, etc., pour construire les flux avec précision.
- Analyse des logs dans Google Cloud’s Operations (Stackdriver), dans CloudWatch for AWS, dans Monitor for Azure, autres*, pour d'emblée connaître les usages de l'information.
- Introspection de certaines technologies de data visualisation "cibles"* qui reposent sur la plateforme Cloud (typiquement Looker, Data Studio pour GCP, ou PowerBI pour Azure ...), pour pouvoir y reconstruire l’« intelligence » en comparant les réponses ;
Pour une compréhension optimale des mutations du système d'information, nous mettons à disposition une cartographie multi-plateformes (source et cible), qui présentera les flux et les usages de l'information.* Certaines de nos réponses sont en cours de développement. 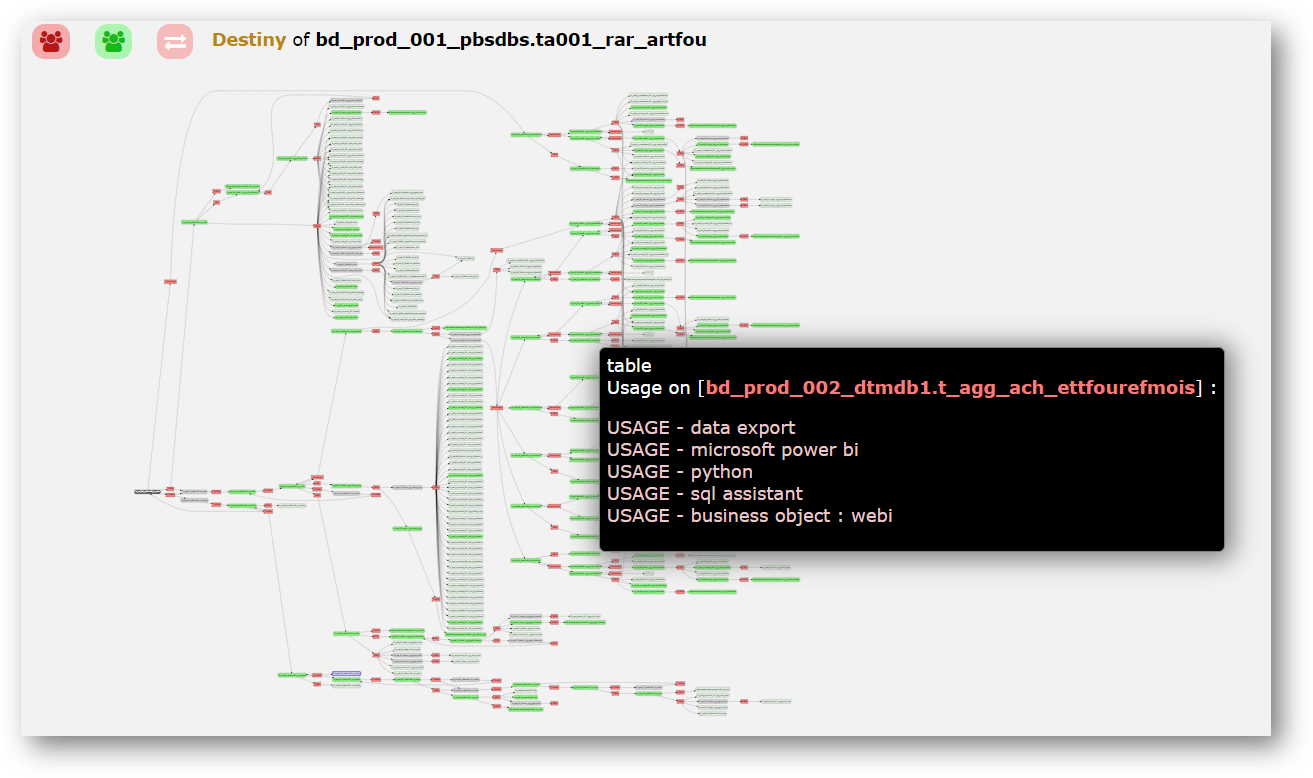
 Etape #3 :
Etape #3 :
"Traduire" le langage source vers le langage cible- {openAudit} va « parser » le T-SQL, le PL/SQL, le Cobol, le Perl, et tout autre langage procédural, et va décomposer toute la complexité du code en source,
- {openAudit} en déduit la cinématique d’ensemble et l’intelligence,
- Sur cette base, {openAudit} va produire du « SQL standard »,
- Puis l’intelligence va être reconstruite a minima dans le SQL spécifique de la base de données cible (qui sont des "dialectes" SQL !),
- Tous les traitements complexes non reproductibles en SQL simple, seront pilotés par un exécutable NodeJS.
Il est ainsi possible d'accélérer massivement le tempo de sa migration !- Et une fois dans le Cloud ?Le risque de l'inflation informationnelle avec les architecture Cloud type "Data Mesh" :L’objectif du Data Mesh est de favoriser la flexibilité maximale, pour créer de nouveaux "business insights", avec des données prêtes à emploi, validées par leurs propriétaires fonctionnels. Et c'est efficace ! Certaines entreprises ambitionnent de devenir "data driven", et le Data Mesh est un puissant catalyseur de cette stratégie.
Cependant les impératifs de maîtrise du processing de la donnée dans des chaines d’alimentation, de fait hyper intriquées, peut vite devenir un « pain point » et rendre la stratégie périlleuse. 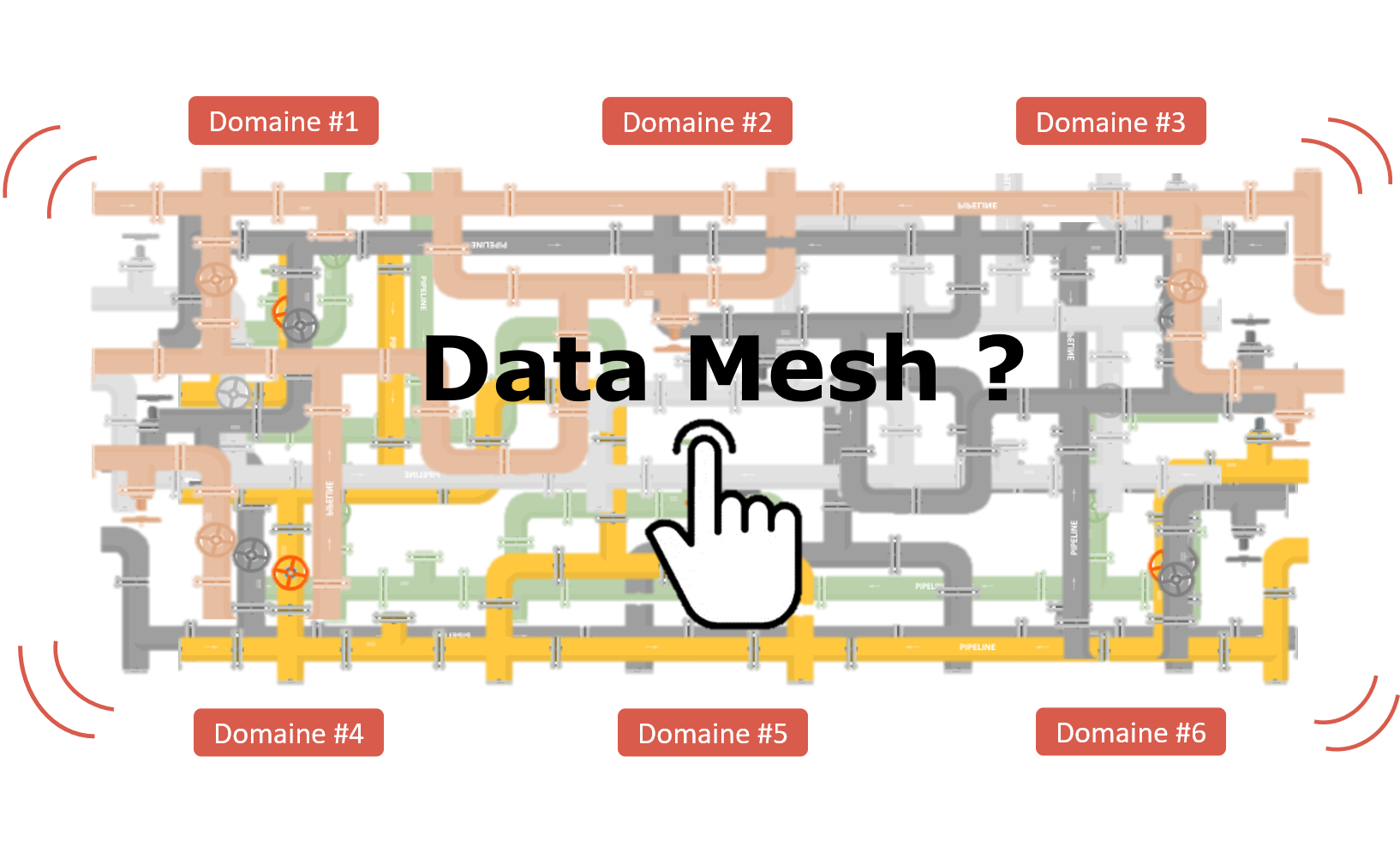
- L'expérience de ADEO/Leroy MerlinTeradata > GCP
Atelier Salon Big Data Paris 2022



Commentaires
Enregistrer un commentaire