Zoom in Zoom out dans les systèmes complexes
 Zoom In,Zoom Outdans lesSI complexes
Zoom In,Zoom Outdans lesSI complexes
- Pourquoi une cartographie « high level » <> « granulaire », d’un Système d'Information ?

2 partis pris techniques :- Cette cartographie doit être dynamique, et être le reflet de l’exact réalité du système à l’instant « t ».
- Cette cartographie doit être technique, non déclarative : elle s’appuiera sur des processus réels, c'est à dire l'analyse continue des flux (code procedural, ETL/ELT, ESB, transformation dans la couche de data visualisation…), et l'analyse de certains logs pour connaître les usages de l’information.
- 1 - Une cartographie « High Level » du SI
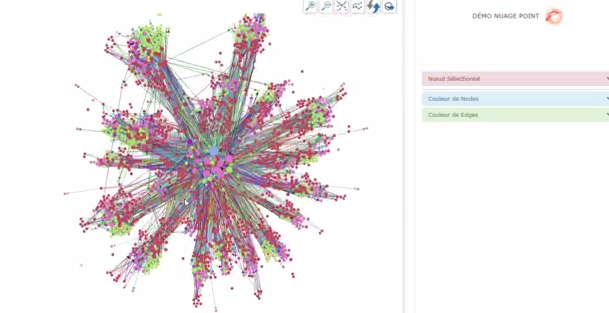
- Cette représentation permet de comprendre l'importance de chaque « data point » : où sont les zones stratégiques dans un SI, les zones « chaudes », les zones « froides », les principales « autoroutes de l’information » entre les grands ensembles du SI, et a contrario, les dépendances inexistantes.Quelques statistiques permettent d'aider les architectes du SI à poser un diagnostic objectif sur l’état de leur système, et à déployer des plans d’action pour aller vers leurs cibles.
- 2 - Premier zoom : des flux complets, et lesusages de l'information
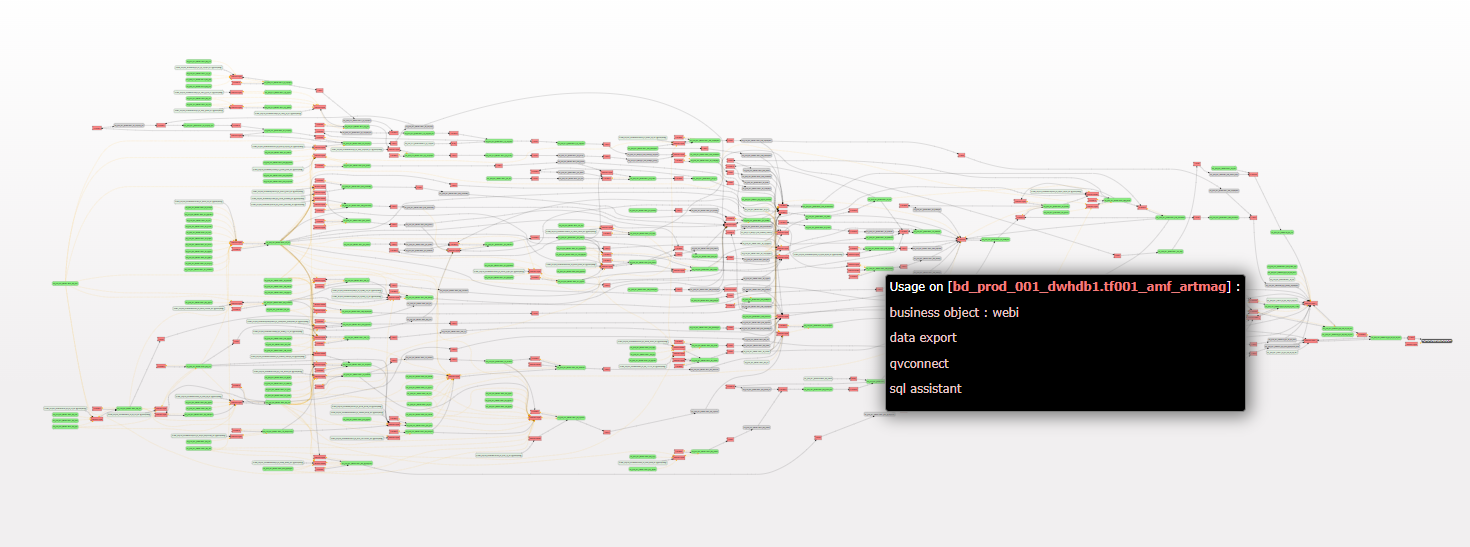
- Cette représentation permet de découvrir de façon visuelle la façon dont l’information s’est déplacée/transformée. En choisissant 2 « data points » (table, champs...) du SI, potentiellement très distants, toutes les transformations intermédiaires sont mises en lumière.Cette vision permettra aux équipes de data engineers d’avoir une vision simple et factuelle de flux complets en 2 clics de souris, qu’ils soient sur leur infra, dans le Cloud, ou les 2.
- 3 - Second zoom : une représentation granulairedes flux et leurs usages à travers le data lineage
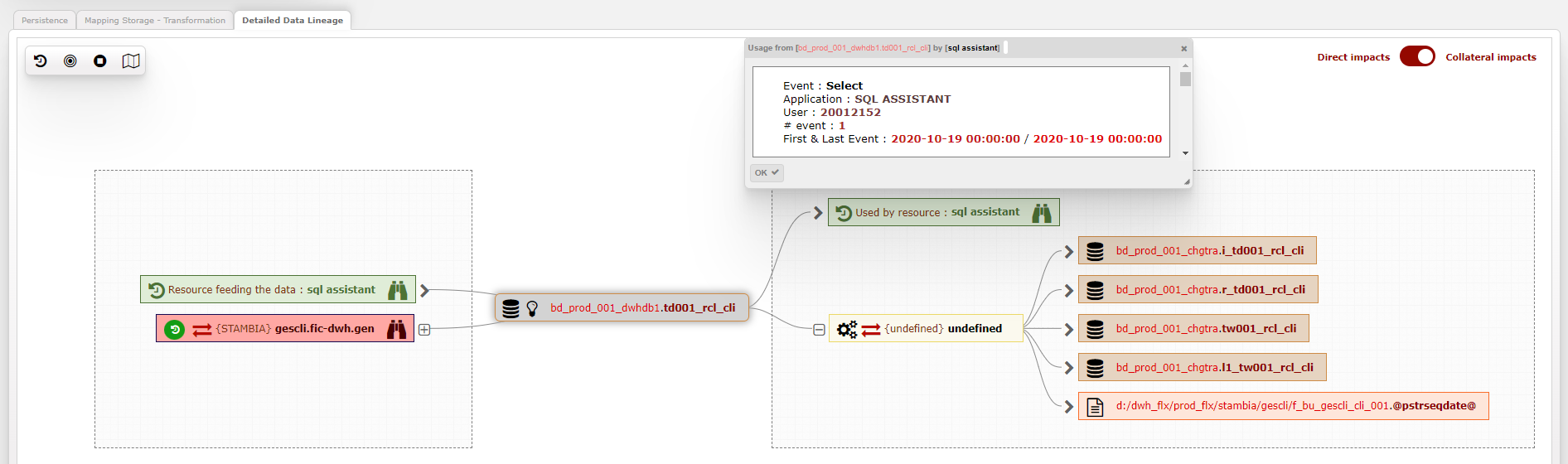
- Cette représentation, un véritable « data lineage » granulaire, permet au départ d’un « data point » (table, fichier, champs), de dérouler les flux dans toutes les directions, quelle que soit la technologie de transformation de données, pour en connaître les sources ou les cibles finales (usages), le code sous-jacent, les dates d’exécution, et toutes précisions techniques utiles.
Les équipes de data engineer pourront faire de l’analyse d’impact, résoudre des problèmes de chaînes qui sont lentes ou inopérantes, trop complexes, etc. - Ainsi, il est possible d'avoir 3 types de cartographies d'un système d'information avec une granularité variable, et avec des ponts de l'une à l'autre.Cela permettra des approches différentes mais complémentaires pour améliorer continuellement la gouvernance du SI.



Commentaires
Enregistrer un commentaire