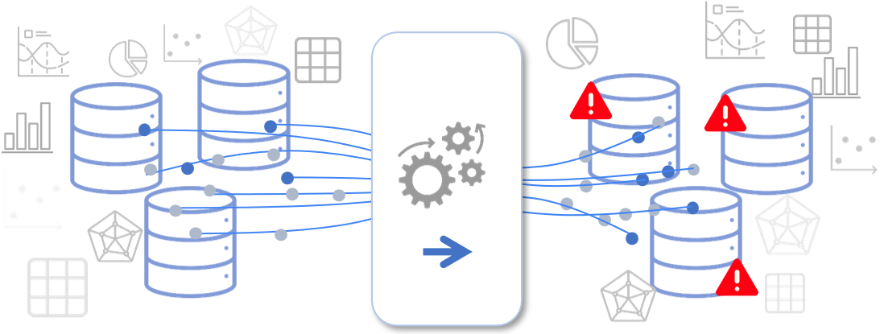
La 1ère action de modernisation d’un Système d'Information : Ecarter les pipelines inutiles ? Un système de données pourrait être comparé à un vaste réseau routier, composé de voies diverses, chacune créée pour répondre à un besoin spécifique à un moment donné. Quand ce réseau se déploie et vieillit, certaines voies (data pipelines) deviennent sous-utilisées ou inutilisées (répliquées, obsolètes). Les impacts financiers et organisationnels sont nombreux : 60 % des données dans le Cloud ne sont pas utilisées selon NTT. Source : IT Social Selon Civo, pour pratiquement la moitié des entreprises de plus de 500 salariés, le coût annuel du Cloud dépasse le million de dollars, avec des taux de croissance difficilement soutenables. Source : ChannelNews L’origine de ces data pipelines inutiles, ces "voies fantômes" ? Avec le temps, les Systèmes d’Information agrègent des pipelines devenus inutiles : Pipelines créés pour des projets désorm...
 !
! .
.





 ), pour une interopérabilité complète, des sources mais aussi de la couche sémantique.
), pour une interopérabilité complète, des sources mais aussi de la couche sémantique.
Commentaires
Enregistrer un commentaire